在數字化浪潮的沖擊下,基于產品質量安全監管的信息化基礎,運用大數據、自然語言處理、機器學習等技術,讓信息橫向在不同區域間、縱向在各級市場監管部門流通,是一個有重要意義且需要我們在業務支撐工作中不斷思考的議題。
為了實現數據賦能,一方面要實現數據的持續有效匯集,另一方面要加強數據分析挖掘能力,從而有效感知數據。目前產品質量監督抽查的數據來源主要包括國家監督抽查和地方監督抽查,從抽查特點看,國家監督抽查側重在輿情關注度較高、風險隱患較大的產品領域開展,而地方監督抽查聚焦區域內的重要業態,具有產品覆蓋范圍廣、數據量大的特點,是產品質量監測工作體系的重要數據組成,占監督抽查數據總量的90%以上,數據中隱藏著大量行業、地區監管薄弱點和質量提升重點的信息。然而開展數據分析首先需要準確標識產品分類,才能實現區域間產品質量安全信息的共享和業務協同。2018年以來,上報的地方監督抽查數據達到176萬批次1 ,產品命名超過9萬種,其中超過95%的產品無法對應到現有抽查用產品分類目錄,存在產品名稱表述不一致、類別劃分不統一等問題,嚴重制約了全國監督抽查數據的全面匯總分析和精準監管工作的有效開展,不利于在全國層面形成監管合力。
目前,地方監督抽查數據通過系統直接填報、前置機交換、數據表導入等三種方式進行上報。從數據特點看,地方監督抽查的產品名稱具有文本短小,特征稀疏、語法不規范等特點,相比于長文本,短文本的特點是信息量少,表達簡潔,以致往往需要更加精準的分類技術來處理,才能實現將通過多種數據采集方式匯聚整合的地方監督抽查數據資源按產品大類到行業再到具體產品的分類。
二、研究思路
目前對產品名稱進行分類的核心方法一般是基于傳統的機器學習算法和深度學習算法。傳統的機器學習算法包括:支持向量機(SVM)和樸素貝葉斯分類器(Naive Bayes Classifier)。SVM是一種監督學習算法,通常用于分類和回歸任務。它的主要目標是找到一個最佳的超平面(或超平面組),以便在不同類別的數據點之間建立一個最大的間隔。這個最大間隔的超平面可以用于對新數據點進行分類,而且在許多情況下具有很好的泛化性能,且在高維空間中表現出色,能夠處理具有許多特征的數據。樸素貝葉斯分類器是一種基于貝葉斯定理的概率分類算法。優勢在于簡單高效,訓練過程很快,且適用于文本分類任務,對高維度的數據能夠很好的處理詞匯的稀疏性,且對小規模數據集上有較好的表現。
而深度學習算法更聚焦在短文本的分類上,更貼合針對產品名稱分類的模式,其中深度學習模型包括:TextCNN和FastText。TextCNN是一個使用卷積神經網絡架構的文本分類模型。它的設計目標是通過卷積操作來捕獲文本中的局部特征,然后通過全局池化層來整合這些局部特征以進行分類。TextCNN的主要組成部分有詞嵌入層、卷積層、池化層、全連接層以及輸出層。TextCNN的優勢在于它的簡單性和高效性,適用于文本分類任務,尤其是短文本分類。
而FastText是一種快速文本分類模型,它引入了子詞嵌入和平均池化操作。FastText算法的核心思想是通過學習詞嵌入向量,將單詞表示為連續的實數向量,以捕捉詞匯之間的語義關系。FastText主要包括構建詞袋和學習詞嵌入,其中學習詞嵌入的模型有CBOW和Skip-gram,這些模型的目標是通過上下文單詞的信息來預測目標單詞。其中CBOW模型是給定上下文單詞的嵌入向量,通過平均化獲得目標單詞的向量表示,從而預測目標單詞。Skip-gram模型是試圖預測上下文單詞,每個目標單詞會生成多個訓練樣本使模型學習到更多豐富和具體的單詞嵌入。
對2018年以來各省通過中國電子質量監督系統上報的地抽數據中產品名稱進行提取和清洗,從9萬條數據中得到6萬條物品名稱清晰、物品分類明確、可進行訓練的數據。為了達到最優的產品名稱分類效果,對數據分別進行三種不同算法的訓練,包括傳統機器學習SVM以及深度學習中的TextCNN和FastText算法。
首先對數據進行分詞、停用詞以及詞向量模型的預訓練,然后將詞向量整合成一個句向量作為模型的輸入進行訓練。通過分析文本的字符組成,將特殊符號、英文符號、數字進行過濾,以減少對產品名稱分類的影響。例如100ml密封盒和500ML塑料盒,本質上兩種物品在分類的過程中都應該屬于食品相關產品,為減少包含100、500、ml等數字、英文以及特殊符號的產品名稱在算法學習過程中對產品分類的判斷,在詞組預訓練過程中,對相應的不同容積、不同型號等影響算法分類的文本進行預處理。
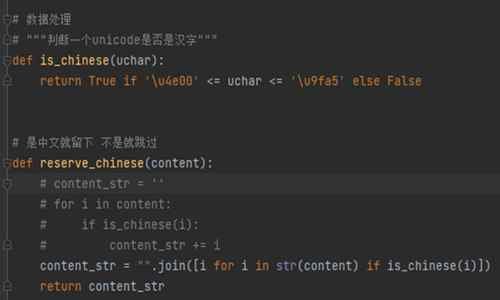
圖1 過濾特殊符號、英文符號和數字
此外,再對重復的數據進行清洗,并按照已分類種類標簽出現的頻次降序排列,保存其index索引值、對應的種類標簽和出現的頻次,為避免出現頻次過少的種類對模型產生過多影響,設置相應的閾值,控制模型學習時使用的數據集,從而提高模型對于整體數據分類的準確性。

圖2 數據預訓練處理
接著構造模型所需要的訓練數據結構,使用目前自然語言處理最流行的jieba模塊進行分詞處理,完成預訓練前數據準備。
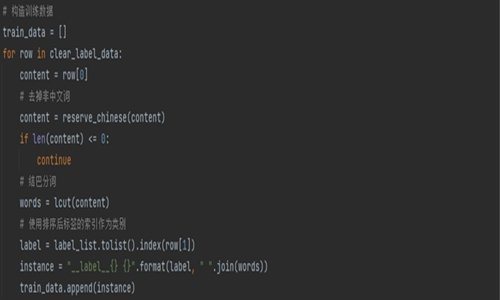
圖3 構造訓練數據
利用jieba庫中的lcut方法,采用基于前綴詞典的前向最大匹配算法,在模型訓練完成后保存相應預處理的分詞文本列表。

圖4 生成預訓練模型及保存處理后數據
然后,根據預測數據的正確率反向調整上述模型算法的參數,從而得到更好的預測結果。包括lr學習率、minCount最低詞頻、minn最小詞長、maxn最大詞長、loss損失函數、epoch迭代次數等,通過修改train_supervised函數中傳遞的參數,對模型訓練的結果進行動態調整。

圖5 調整模型參數
從算法的運行結果看,目前三種算法得到的訓練準確率分別為:支持向量機SVM算法81.5%,TextCNN算法59.2%,FastText算法86.3%。在對測試集的訓練中,FastText表現效果更好。
從現有的數據情況看,存在如下問題:(1)訓練數據的規模較小。對于有近900項產品分類的模型,訓練集的數據規模通常在百萬級以上,且要保證訓練數據集涵蓋了各種產品類別、形狀、顏色、尺寸等方面的差異,以使模型能夠更好地進行分類。(2)數據質量有待提高。目前僅有6萬條數據符合模型訓練,且存在錯誤標記的情況,因此標簽質量仍需提高,避免因數據質量影響模型性能。(3)數據的偏置現象。在清洗后的數據中,約有20%的數據是食品相關產品類,排名前十的分類共占約50%的數據總量。由于模型在學習過程中會傾向于過度關注這些類別,導致也會更傾向于預測這些類別,然而在實際預測新的數據過程中,這些類別可能不是絕大多數的產品的正確類別,導致模型預測出現誤差。
下一步,考慮對數據分類進行有效合并,從而簡化問題。此外,針對有效數據量較少的問題,除挖掘更多可以利用的數據外,也可以利用數據增強等技術來生成更多的訓練數據,包括同義詞替換、文本翻轉、隨機插入等方式,有助于提高模型的泛化能力。針對數據分布不均勻以及預測傾向問題,可以通過欠采樣和過采樣以及修改數據權重等方法,對于數據集中數量較多的類別,可以進行欠采樣或者減小權重;對于數量較少的類別,可以進行過采樣或者增加權重,確保每個類別的樣本數量相對均衡,從而解決數據分布不均勻的問題。預測傾向問題可以采用TOP N策略,預測前N個可能的類別,而不僅僅是最可能的一個,有助于避免模型過于集中在前幾個類別上。
在后續的模型訓練過程中,也應實時監控模型的性能,及時發現并解決模型漂移或性能下降的問題。根據實際應用過程中模型訓練結果的反饋,不斷迭代優化訓練模型和模型使用的訓練數據集。
一、研究背景在數字化浪潮的沖擊下,基于產品質量安全監管的信息化基礎,運用大數據、自然語言處理、機器學習等技術,讓信息橫向在不同區域間、縱向在各級市場監管部門流通,是一個有重要意義且需要我們在業務支撐工......
一、研究背景在數字化浪潮的沖擊下,基于產品質量安全監管的信息化基礎,運用大數據、自然語言處理、機器學習等技術,讓信息橫向在不同區域間、縱向在各級市場監管部門流通,是一個有重要意義且需要我們在業務支撐工......
一、研究背景在數字化浪潮的沖擊下,基于產品質量安全監管的信息化基礎,運用大數據、自然語言處理、機器學習等技術,讓信息橫向在不同區域間、縱向在各級市場監管部門流通,是一個有重要意義且需要我們在業務支撐工......
美國西北大學、波士頓學院和麻省理工學院研究人員從人腦中汲取靈感,開發出一種能夠進行更高層次思維的新型突觸晶體管,可像人腦一樣同時處理和存儲信息。在新的實驗中,研究人員證明晶體管對數據進行分類的能力,超......
GuardantHealth、CancerResearchUK及其創新單位癌癥研究Horizons周一宣布,它們已達成一項合作協議,旨在探討共享技術、數據和見解,推動精準癌癥檢測和治療的發展。各方表示......
GuardantHealth、CancerResearchUK及其創新單位癌癥研究Horizons周一宣布,它們已達成一項合作協議,旨在探討共享技術、數據和見解,推動精準癌癥檢測和治療的發展。各方表示......
23andMe于周一披露,10月份的數據泄露影響了總共690萬用戶檔案。在上周五的一份監管文件中,這家消費者基因測試公司表示,它的調查發現0.1%,約14,000個用戶賬戶最初被一名威脅行為者使用從其......
12月5日,記者在本市召開的“兩區”建設新聞發布會上了解到,前不久,國務院批復同意《支持北京深化國家服務業擴大開放綜合示范區建設工作方案》(以下簡稱示范區2.0方案),示范區2.0方案圍繞推進服務業重......
近日在上海舉行的2023全球數商大會健康數據高峰論壇上,“生命健康數據空間聯合實驗室”正式揭牌成立。據悉,該實驗室由復旦大學、上海市生物醫藥技術研究院和中國信通院上海工創中心牽頭,復旦大學附屬中山醫院......
近日,衛健委發布《衛生健康信息數據元目錄第1部分:總則》等34項推薦性衛生行業標準,,涉及總則、標識、實驗室檢查、醫學診斷等項目,詳情如下:標準編號標準名稱代替標準編號WS/T363.1—2023衛生......